
{kind=link}
(KTSG) – Việt Nam đang ở những bước đầu của việc soạn thảo luật liên quan đến dữ liệu cá nhân. Đây cũng là giai đoạn trí tuệ nhân tạo (AI) nở rộ, đi sâu vào đời sống kinh tế – xã hội. Việc xác định vị thế và hiểu rõ các thách thức sẽ giúp Việt Nam có cách tiếp cận phù hợp với dữ liệu cá nhân – một yếu tố để quản trị tốt công nghệ AI.
- Bảo vệ dữ liệu cá nhân, nhìn từ hoạt động của các tập đoàn đa quốc gia tại Việt Nam
- Vi phạm dữ liệu cá nhân bị xử sao?

Ngày 1-11-2023, Tuyên bố Bletchley được 28 quốc gia ký kết, bao gồm cả hai siêu cường Mỹ và Trung Quốc, trong khuôn khổ Hội nghị Cấp cao về An toàn AI (AI Safety Summit) tại Vương quốc Anh cho thấy một nỗ lực toàn cầu trong quản trị công nghệ AI. Tuyên bố này, tuy không có sự tham gia của Việt Nam, nhưng có hàm ý cho Việt Nam rằng với một mục tiêu là phát triển công nghệ AI vì cuộc sống tốt hơn cho con người, các nhà lãnh đạo tại Việt Nam phải đối diện với hai thách thức tương tự các nhà lãnh đạo trên thế giới là triển khai ứng dụng AI vào đời sống kinh tế – xã hội và quản lý rủi ro của AI tạo ra đối với con người.
Cả hai thách thức này đều liên quan đến một đối tượng là dữ liệu mà trong đó dữ liệu cá nhân đóng vai trò hạt nhân. Do đó, xác định được một cách tiếp cận chính sách phù hợp đối với dữ liệu cá nhân là một trong những yếu tố để Việt Nam quản trị tốt công nghệ AI.
Việt Nam ở đâu trong hệ sinh thái công nghệ số toàn cầu?
Câu hỏi Việt Nam ở đâu trong hệ sinh thái công nghệ số toàn cầu được đặt ra nhằm làm rõ mức độ gắn kết của Việt Nam với thế giới thay vì tìm kiếm thứ hạng của Việt Nam trên bản đồ thế giới công nghệ ngày nay.
Một hệ sinh thái công nghệ số có thể được mô tả đơn giản nhất với sự tham gia của ba thành tố: (1) cơ sở hạ tầng với cáp quang biển, trạm thu phát đóng vai trò truyền đưa dữ liệu và các trung tâm dữ liệu, dịch vụ điện toán đám mây đóng vai trò lưu trữ dữ liệu; (2) thiết bị thông minh như điện thoại, máy tính đóng vai trò kết nối cá nhân với mạng Internet và (3) dịch vụ trên Internet như mạng xã hội, mua sắm trực tuyến, tìm kiếm trực tuyến… được cung cấp đến từng cá nhân.
Trong hệ sinh thái này, Việt Nam có mức độ gắn kết cao, khó tách rời. Cả nước có năm tuyến cáp quang biển kết nối đi quốc tế. Theo số liệu của Bộ Thông tin và Truyền thông năm 2020, 80% thị phần dịch vụ điện toán đám mây thuộc về các nhà cung cấp xuyên biên giới như Microsoft, Amazon Web Services, Google, Alibaba… Việt Nam nằm trong số 10 quốc gia có lưu lượng dữ liệu xuyên biên giới lớn nhất thế giới và mức độ tăng trưởng cũng lớn nhất thế giới tính đến năm 2019, theo Nikkei Asia. Các dịch vụ nền tảng phổ biến trên Internet như Google Search, App Store, Facebook, Youtube… hầu hết được cung cấp xuyên biên giới vào Việt Nam. Cùng với việc 70% dân số sử dụng Internet, dữ liệu (bao gồm dữ liệu cá nhân) đang chảy xuyên quốc gia giúp kết nối Việt Nam với thế giới.
Dữ liệu cá nhân trong sự phát triển của AI
Đặc tính kết nối xuyên biên giới của dữ liệu cá nhân sẽ tiếp tục được củng cố trong tiến trình phát triển của công nghệ AI. Theo nhà khoa học máy tính Kai – Fu Lee, AI sẽ trải qua bốn giai đoạn phát triển, từ AI Internet, AI kinh doanh, AI nhận thức cho đến AI tự quản (hình 1).
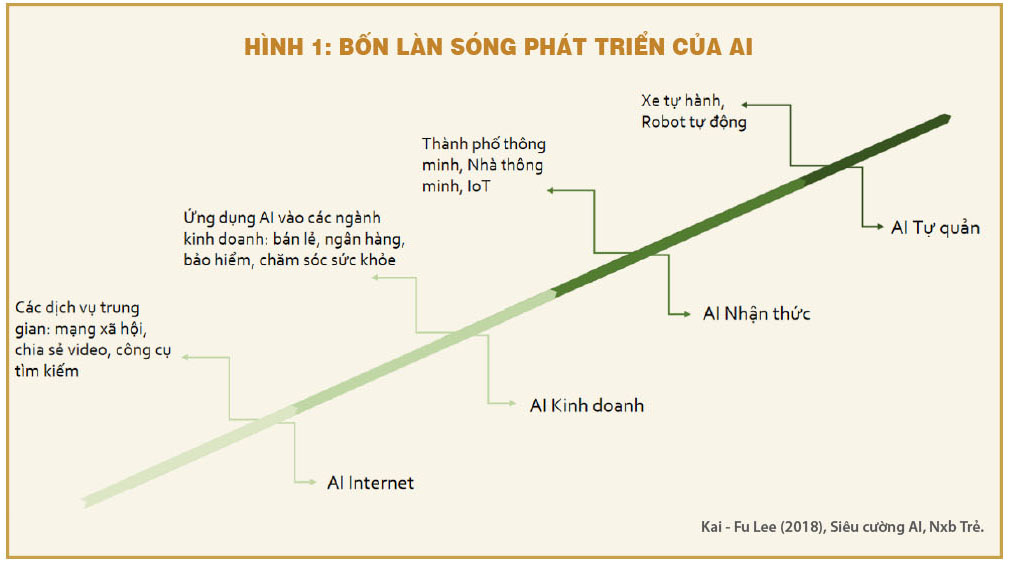
Tất cả những giải pháp công nghệ được triển khai dựa trên AI đều đòi hỏi lượng lớn dữ liệu lớn đầu vào cho phép máy tính toán ra xác suất gần đúng nhất. Chẳng hạn để cung cấp dịch vụ tín dụng cá nhân tối ưu nhất, ngân hàng cần thu thập nhiều loại dữ liệu cá nhân khác nhau có thể như lịch sử việc làm, chi tiêu, vay vốn, thu nhập, thói quen mua sắm, gia cảnh, mối quan hệ xã hội… Thậm chí, sở thích và tính cách cũng dùng để tính toán khả năng thanh toán của cá nhân đối với khoản vay tín dụng nhằm giảm thiểu rủi ro nợ xấu cho ngân hàng. Hoặc trong thành phố thông minh, cơ quan điều hành phải thu thập dữ liệu từ tất cả người dân, phương tiện, thiết bị, tòa nhà để điều phối hệ thống giao thông, phát hiện tội phạm, mạng lưới cấp điện và cấp nước nhằm tối ưu hóa nguồn lực, nâng cao chất lượng cuộc sống của người dân.
Từ đây, cũng thấy một nguyên tắc là để mỗi bước phát triển của AI phục vụ tốt hơn cho con người, AI bắt buộc phải được đào tạo dựa trên dữ liệu do con người tạo ra. Thế nhưng việc tạo ra giải pháp cho một vấn đề cũng đồng thời tạo những một vấn đề mới. Trong trường hợp này, đó là bất bình đẳng và quyền riêng tư.
Bất bình đẳng và quyền riêng tư
Sự chênh lệch về khả năng kiểm soát dữ liệu để đưa ra các quyết định gây ra sự bất bình đẳng trong hưởng thụ giữa các nhóm trong xã hội. Trong mô hình kinh tế vận hành dựa trên dữ liệu, chủ thể có khả năng kiểm soát và khai thác được khối lượng dữ liệu càng lớn sẽ thu được lợi ích càng cao. Chẳng hạn, trong làn sóng AI Internet, các chủ thể kiểm soát dữ liệu cá nhân như Google, Facebook, TikTok với tiềm lực công nghệ đã và đang có lợi thế trong việc thấu hiểu, dự đoán sở thích, hành vi của người dùng để bán các quảng cáo cá nhân hóa nhằm thúc đẩy người dùng chi tiêu. Trong khi đó, hầu hết người dùng không có khả năng để hiểu biết về dữ liệu cá nhân của họ được xử lý như thế nào và hành vi của họ chịu tác động ra sao.
Trong các làn sóng AI tiếp theo, các chủ thể vốn có lợi thế về công nghệ và dữ liệu như Google, Facebook, TikTok hay chủ thể nào có đủ tiềm lực để tham gia vào khai thác dữ liệu sẽ luôn giữ lợi thế kinh doanh và hưởng phần lợi ích lớn hơn với hầu hết phần còn lại của xã hội.
Cùng với đó, quyền riêng tư của các cá nhân trong không gian số cũng sẽ bị ảnh hưởng. Các chủ thể của dữ liệu cá nhân khó để kiểm soát những ai được biết và biết những thông tin nào về mình. Cũng do sự bất bình đẳng trong quyền kiểm soát dữ liệu cá nhân, quyền riêng tư của các chủ thể rất dễ bị tổn thương.
Mặt khác, khi một cá nhân kết nối vào hệ sinh thái công nghệ số toàn cầu, việc thực thi các quyền kiểm soát dữ liệu có thể được quy định bằng các thủ tục hành chính nhưng về mặt kỹ thuật rất khó để đi vào thực tế.
Cơ hội chính sách cho “trâu chậm”
Để giải quyết bài toán về bất bình đẳng liên quan đến dữ liệu cá nhân cần cách tiếp cận tổng thể từ nhiều khía cạnh khác nhau gồm thuế, lao động, giáo dục đào tạo, an sinh xã hội. Riêng khía cạnh quyền riêng tư, tại Việt Nam hiện nay, Luật An ninh mạng 2018, Nghị định 53 quy định chi tiết một số điều của luật trên và Nghị định 13 về bảo vệ dữ liệu cá nhân là ba văn bản quy phạm pháp luật liên quan trực tiếp đến vấn đề này. Các văn bản là cần thiết nhưng chưa thực sự gia tăng quyền kiểm soát dữ liệu cá nhân cho các chủ thể, thậm chí, một số chi tiết còn dựng lên các rào cản cả kỹ thuật và phi kỹ thuật đối với hoạt động xử lý dữ liệu chính đáng.
Việt Nam nên xác định hai trụ cột chính trong tiếp cận chính sách đối với dữ liệu cá nhân là đảm bảo tự do dữ liệu và an toàn dữ liệu. Tự do dữ liệu được hiểu là dữ liệu cá nhân được lưu chuyển xuyên quốc gia mà không gặp phải các rào cản kỹ thuật, phi kỹ thuật. Khi đó, khả năng kết nối của Việt Nam trong hệ sinh thái công nghệ số toàn cầu được đảm bảo, tuân thủ các cam kết thương mại tự do để phát triển kinh tế.
An toàn dữ liệu được hiểu là công khai và minh bạch trong quy trình xử lý dữ liệu cá nhân. Cá nhân nhận thức rõ về khả năng tự do đưa ra quyết định của mình trước các lựa chọn. Mỗi người hiểu rõ bảo mật dữ liệu bằng các biện pháp kỹ thuật tương ứng với mức độ rủi ro gây ra đối với danh dự, nhân phẩm, sức khỏe của chính mình.
Cách tiếp cận này cần được tiếp tục chuyển tải vào từng quy định pháp luật cụ thể để tạo thành hành lang pháp lý phù hợp cho hoạt động xử lý, bảo vệ dữ liệu cá nhân tại Việt Nam. Bước đầu soạn thảo luật về dữ liệu cá nhân hiện nay vốn tưởng là chậm chân nhưng lại trở thành một cơ hội tốt để Việt Nam hoàn thiện cách tiếp cận đối với dữ liệu cá nhân phù hợp với thực tế phát triển lan rộng của AI.
(*) Viện Nghiên cứu Chính sách và Phát triển Truyền thông (IPS)